
Привет! Сегодня хотел бы рассказать как можно развернуть на своей локальной машине аналог чата GPT. Особых знаний для этого иметь не нужно. Все достаточно просто.
Для тех кто не знает что такое chatGTP, то это чат-бот с генеративным искусственным интеллектом, разработанный компанией OpenAI и способный работать в диалоговом режиме, поддерживающий запросы на естественных языках. ( кусок из Викепедии )
Но возможно не все знают, что существуют альтернативные чат боты, платные и бесплатные, централизованные и децентрализованные
Существует несколько популярных моделей с открытым исходным кодом, которые можно развернуть локально:
Эти модели предоставляют функциональность, схожую с ChatGPT, но менее мощные.
Так же существуют децентрализованные аналоги чата GPT но тут я не буду об этом писать, хотя тема децентрализации подобных систем мне кажется достаточно интересной.
По-своей сути подобные чаты представляют из себя ML-модели
ML (Machine Learning) — это технология, позволяющая компьютерам обучаться и принимать решения на основе данных, не будучи явно запрограммированными. ML-модель — это математическое представление данных и логики, которое позволяет системе делать предсказания или выполнять задачи, анализируя входные данные.
Основные этапы работы ML-модели:
- Сбор данных: Системе нужны данные для обучения.
- Обработка данных: Данные очищаются, нормализуются и подготавливаются для анализа.
- Обучение: Модель обучается на данных, выявляя закономерности и зависимости.
- Валидация: Проверяется, как хорошо модель работает на новых данных.
- Применение: Обученная модель используется для анализа новых данных.
Типы ML-моделей:
- Супервизорное обучение (Supervised Learning): Обучение на размеченных данных (например, классификация писем как «спам» или «не спам»).
- Без учителя (Unsupervised Learning): Выявление скрытых структур в неразмеченных данных (например, кластеризация клиентов).
- Обучение с подкреплением (Reinforcement Learning): Модель учится через награды за правильные действия (например, обучение робота).
Для чего это вообще может пригодится в быту? Да для чего угодно :) На базе генеративного чата ИИ вы можете создать своего персонального помощника, который сможет предоставлять вам те данные, которые вам необходим, например, в работе. При этом он будет работать автономно на вашем компьютере и абсолютно бесплатно, так он вполне работает без подключения к интернету.
В данной статье я бы хотел продемонстрировать как достаточно просто можно развернуть чат ollana, пару слов о том, что из себя представляет ollama
Ollama — это платформа и инструмент для локальной работы с большими языковыми моделями (LLM, Large Language Models). Она позволяет запускать и использовать LLM прямо на вашем устройстве, не требуя обращения к внешним серверам.
Основные особенности Ollama:
- Локальная работа: Запуск моделей происходит локально, что повышает конфиденциальность и безопасность.
- Оптимизация: Использует аппаратные ресурсы устройства максимально эффективно.
- Поддержка популярных моделей: Ollama работает с различными открытыми и специализированными языковыми моделями, включая модели вроде Llama 2, Alpaca, или GPT.
Модели: Ollama предоставляет доступ к языковым моделям, которые работают с текстами. Это может быть генерация текста, обработка запросов, написание кода и многое другое.
Технология:
- Использует LLM, которые обучены на огромных текстовых датасетах.
- Поддерживает работу с моделями, оптимизированными для локального запуска.
- Совместима с архитектурами, такими как Transformer, лежащими в основе современных LLM.
Применение:
- Генерация текста (автоматизация переписки, написание статей).
- Классификация (определение тематики текста).
- Анализ (суммаризация текста, ответ на вопросы).
Ollama может использовать любые модели, доступные в формате GGML, подходящем для локального запуска.
По управлению ollama немного напоминает docker
Для установки ollama нужно перейти на официальный сайт и скачать версию для вашей операционной системы
После установке можно запустить ollama выполнив команду в консоле:
$ ollama run llama3.2
Данная команда скачает и запустит модель llama3.2
Список моделей доступных для ollama можно посмотреть тут модели могут быть мощными 90B и выше, так и менее мощными 2B
Можно установить любое количество моделей ( если у вас хватает ресурсов ), для просмотра уже скаченных моделей можно воспользоваться командой:
$ ollama list NAME ID SIZE MODIFIED codestral:22b 0898a8b286d5 12 GB 12 hours ago phi:latest e2fd6321a5fe 1.6 GB 14 hours ago llama3.2:latest a80c4f17acd5 2.0 GB 4 days ago
Так же хотелось бы отметить, что такое 2B, 90B. Это обозначения, которые указывают на количество параметров в машинной модели (в миллиардах, где B означает billion — миллиард). Параметры — это числовые значения, которые модель настраивает во время обучения для выполнения задач, таких как обработка текста или генерация ответов. К примеру, GPT-4 использует 1.8 триллиона параметров (или 1,800 миллиардов)
Большие и мощные модели потребуют больших ресурсов компьютера для работы. Они потребляют больше процессорной мощности, памяти и занимают достаточно большой объем жесткого диска.
И так, после выполнения команды, мы уже сможем работать с чатом из командной строки.
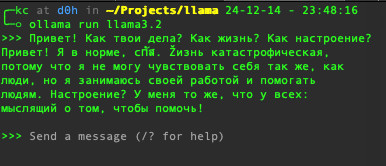
так же после запуска чат доступен по адресу http://localhost:11434, по которому можно обратится, сформировав HTTP запрос. Вот пример как это сделать:
На curl из командной строки:
curl -X POST http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"prompt": "Привет! Как дела?",
"stream": false
}'
Получаем ответ, что-то вроде:
{
"model": "llama3.2",
"created_at": "2024-12-14T22:15:02.891574Z",
"response": "Здравствуйте! Я работаю нормально, gracias за вопрос. Как youre?",
"done": true,
"done_reason": "stop",
"context": [
...
],
"total_duration": 1162500333,
"load_duration": 50502583,
"prompt_eval_count": 32,
"prompt_eval_duration": 618000000,
"eval_count": 20,
"eval_duration": 491000000
}
Тут важно отметить, что если не передать в теле запроса «stream»: false то ответ будет возвращаться в виде так называемых чанков, на каждое генерацию ответа:
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.01656Z","response":"Пр","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.032929Z","response":"ив","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.054271Z","response":"ет","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.076969Z","response":"!","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.098469Z","response":" Как","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.122245Z","response":" я","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.144477Z","response":" могу","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.165088Z","response":" пом","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.186886Z","response":"очь","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.207423Z","response":" вам","done":false}
{"model":"llama3.2","created_at":"2024-12-14T22:12:32.229528Z","response":"?","done":false}
...
Так же к чату можно обращаться из своих скриптов, вот простой пример скрипта на PHP:
<?php
$url = 'http://localhost:11434/api/generate';
$data = [
"model" => "llama3.2",
"prompt" => "Привет! Как дела?",
"stream" => true // включение потокового режима
];
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_WRITEFUNCTION, function($curl, $chunk) {
// Обрабатываем чанки текста
$response = json_decode($chunk, true);
if (isset($response['response'])) {
echo $response['response'];
}
return strlen($chunk);
});
curl_exec($ch);
curl_close($ch);
Далее не помешало бы настроить какой-то удобный интерфейс для взаимодействия с ИИ чатом. Для этого можно воспользоваться готовым решением — open-webui
Open-webui — это графический интерфейс при помощи которого можно подключаться как к локальным так и к удаленным генеративным моделя наподобие chatGPT или LLaMa
open-webui можно установить локально ( для этого потребуется установить Paython ) или воспользоваться образом из докера. Мне больше нравится работать с докером, поэтому я выбрал вариант с контейнером:
$ docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://host.docker.internal:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Тут важно отметить, что я указал в команде значение переменной -e OLLAMA_BASE_URL=http://host.docker.internal:11434
Она указывает на адрес на котором ollama запускается локально. В моем случае подобный вариант запуска привел к тому, что UI web интерфейса очень сильно тормозил, поэтому в команде я указал вместо http://host.docker.internal:11434 — http://localhost:11434 а уже после запуска изменил адрес на http://host.docker.internal:11434 из панеле управления: Админ Панель -> настройки -> соедниение
После запуска, open-webui будет доступен по адресу http://localhost:3000
Нужно будет зарегистрироваться и можно общаться с чатом:
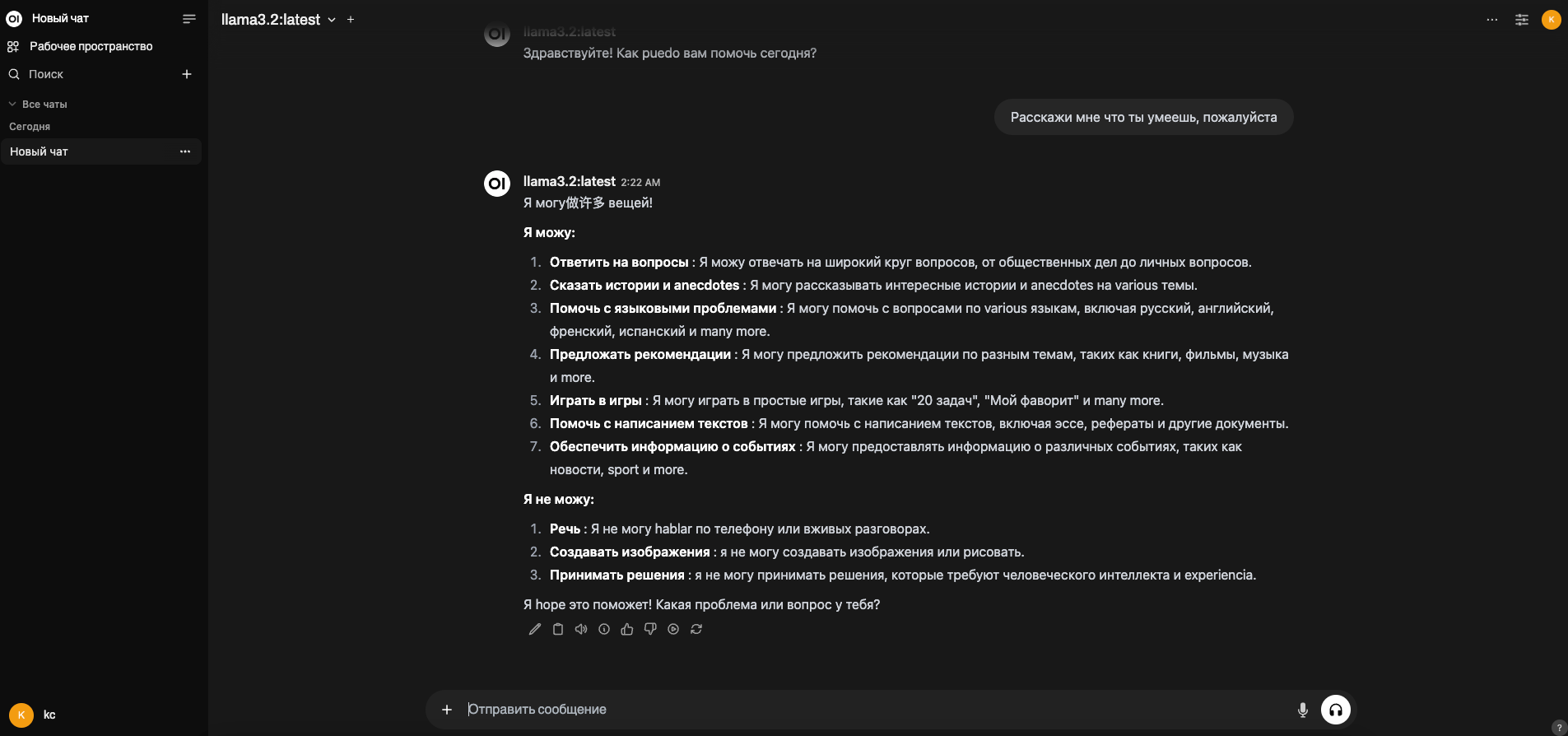
Ну вот и все! Надеюсь данная информация будет полезна кому-нибудь.