Хотел бы показать как достаточно просто создавать Desktop приложения node js на базе библиотеки Electron.
Electron по своей сути это движок браузера — chromium, при помощи которого можно создавать приложения на основе веб сайта или веб сервис, достаточно всего лишь указать url сайта который должен открываться внутри хромиума и собрать приложение под нужную систему.
Тут я продемонстрирую как это сделать для mac os на процессоре arm, но в любой другой системе алгоритм создания приложения будет таким же.
Для демонстрации создания приложения, я выбрал видео сервис Youtube, который будет работать как десктоп приложение mac os. Приложение будет инсталироваться стандартным образом ( через dmg установщик ) особенностью данного приложения будет то что youtube будет запускаться через защищенный канал shadowsock, который можно настроить по инструкции тут
Для начала необходимо установить требуемые пакеты для начала разработки
После того как node js и electron установлены можно приступить к разработке кода приложения
vim index.js
И вот сам код прилаги
require('dotenv').config(); // Загружаем .env
const { app, BrowserWindow, Menu } = require('electron');
const path = require('path');
// Получаем прокси из .env или используем значение по умолчанию
const proxyUrl = process.env.PROXY_URL || 'socks5://127.0.0.1:1080';
// Применяем настройки прокси
app.commandLine.appendSwitch('proxy-server', proxyUrl);
function createWindow() {
// создаем окно, тут можно задать параметры, например отмеить devtools и задать полноэкранный режим при запуске, задать иконку приложения
const win = new BrowserWindow({
width: 1200,
height: 800,
icon: path.join(__dirname, 'icon.icns'),
webPreferences: {
devTools: false
}
});
// Задаем URL который должен подгружатся в наш Chromium
win.loadURL('https://youtube.com');
// Запрет на переход на сторонние ресурсы
win.webContents.on('will-navigate', (event, url) => {
if (!url.includes('youtube.com')) {
event.preventDefault();
win.loadURL('https://youtube.com');
}
});
// Запрет на открытие других ресурсов кроме youtube.com
win.webContents.setWindowOpenHandler(({ url }) => {
if (!url.includes('youtube.com')) {
return { action: 'deny' };
}
return { action: 'allow' };
});
// убираем системное стандартное меню
Menu.setApplicationMenu(null);
}
// Запускаем приложение
app.whenReady().then(createWindow);
Как видно код очень простой и не требуется каких-то серьезных знаний для того чтобы разобраться что он делает, но комментарии я оставил
Теперь нужно собрать пакет установки для нужной системы
Для начала нужно добавить иконку приложения, для этого можно взять картинку ( будущую иконку приложения ) в формате png и конвертировать ее в специальный формат для приложений mac os — incs ( для других систем это будет другой формат иконок, например ico )
Конвертировать картинку из png в incs можно встроенной командой mac os
sips -s format icns icon.png --out icon.icns
Картинка готова! Далее нужно не забыть создать .env файл с одной единственной настройкой — вашим proxy ( sock )
echo 'PROXY_URL=socks5://127.0.0.1:1080' > .env
вместо socks5://127.0.0.1:1080 укажите свой proxy
Проверяем запуск
npx electron .
Если окошко появилось и в нем запустился Youtube то можно приступать к сборки бинарника для вашей архитектуры.
Тут я указал название приложения, указал в качестве платформы darwin ( mac os ) в качестве архитектуры указал архитектуру своего нотпада — arm64
После успешной данной операции уже можно спокойно перетащить готовый app файл из новой директории «YouTube Sock-darwin-arm64» в директорию Applications и запускать полноценное приложение в своей системе, но если хотите создать dmg и поделится готовой сборкой с кем-нибудь то можно еще выполнить вот это
Привет! В Mac OS чаще всего используют программу Tunnelblick для подключения по vpn. Я тоже ей пользовался и это было отвратительно, может у меня кривые руки и я не сумел ее грамотно настроить ( ну те проставить правильно галочки в gui интерефейсе ), но в целом получить от нее стабильности и простоты у меня так и не получилось.
Возможно эта программное обеспечение для подключения к vpn удобно когда тебе нужно подключать по 1 vpn для просмотра ютубчика на обеде ( хотя vpn для этого не нужен, достаточно настроить анонимный proxy ) но когда требуется что-то более сложное Tunnelblick начинает хромать.
Стандартная ситуация, вы работаете в крупной компании и вам требуется использовать корпоративные сервисы, которые развернуты внутри сети. Для этой цели вам выдали vpn.
Так же внутри компании есть разные отделы, например завязанные на какие-то конкретные проекты и внутри корпоративной сети у вас должен так же быть отдельный доступ к внутренним сервисам вашего отдела проекта в котором вы работаете, таким образом вам уже требуется подключаться к 2 vpn сетям одновременно приплюсуем к этому что вы живете в стране в которой часть ресурсов заблокирована из-за непростой геополитической ситуации и вам уже потребуется 3 vpn которые должны работать и не конфликтовать друг с другом.
Tunnelblick с 3 VPN уже работает плохо, давайте еще добавим, что VPN тоже не работает стабильно так как время от времени провайдер тестирует оборудование фильтрации VPN и связь пропадает. Это катастрофа, если вам требуется VPN для работы.
Допустим, еще в вашей компании время от времени обновляются ovpn и его нужно скачивать по специальной ссылке и таким образом, используя гуи приложения для vpn вам придется время от времени заниматься удалением, добавлением и если вы используете еще sock5 для своего подключения — правками ovpn файлов.
Каждый раз после того как Tunnelblick зависал, я грустил и вспоминал времена когда у меня был arch linux и для подключения к vpn я использовал простой скрипт на bash.
Последней каплей стала ситуация когда после обновления ОС, вместе с зависанием Tunnelblick стала пропадать сеть так что требовалась перезагрузка макбука для того чтобы сеть снова появилась ( позже я разобрался с этим и это оказалось, что это из-за того что Tunnelblick не мог правильно возвращал DNS сервера на место ). Это стало последней каплей терпения и я решил окончательно решить этот вопрос и удалив с радостью Tunnelblick написал свой скрипт для подключения к VPN, чем хочу поделится тут.
#!/bin/bash
VPN_PID="$HOME/.vpn/vpn.pid"
LOG_FILE="$HOME/.vpn/vpn_download.log"
# в этом файле нужно прописать ссылки ( каждая на своей строке по которым скрипт будет забирать обновленные ovpn файлы
# содержимое файла ~/.vpn/update.txt должно иметь вот такой вид:
# https://corporate.site/share/project.ovpn
# https://corporate.size/share/corporate.ovpn
URL_LIST_FILE="$HOME/.vpn/update.txt"
# пути к .ovpn файлам
TARGET_DIR="$HOME/.vpn/configs"
VPN_CONFIG_1="$TARGET_DIR/corporate.ovpn"
VPN_CONFIG_2="$TARGET_DIR/project.ovpn"
VPN_CONFIG_3="$TARGET_DIR/private.ovpn"
# логин и пароль от корпоративного VPN
# содержимое файла ~/.vpn/password.auth
# <login_vpn>
# <password_vpn>
VPN_PASSWORD="$HOME/.vpn/password.auth"
# пусть к команде openvpn
# в моем случае я ставил openvpn для mac os через homebrew
VPN_COMMAND="/opt/homebrew/sbin/openvpn"
# замените на ваш DNS
DNS_SERVER="8.8.8.8"
# замените на вашу сеть
NETWORK_SERVICE="Wi-Fi"
# таймауты и настройки проверки подключений к vpn
CHECK_TIMEOUT=10
MAX_ATTEMPTS=3
CONNECT_TIMEOUT=30
# Shadowsocks параметры, как настраивать я писал тут:
# Как настроить Shadowsocks - https://killercoder.ru/maskirovka-trafika-cherez-shadowsocks
# Как установить Shadowsocks - https://killercoder.ru/ustanavlivaem-shadowsocks-na-svoj-server
SHADOWSOCKS=false
SHADOWSOCKS_PROXY="socks5://127.0.0.1:1080"
# Парсинг аргументов
# Поддерживает 1 аргумент --sock ( подключение через sock proxy )
while [[ $# -gt 0 ]]; do
case "$1" in
--sock)
SHADOWSOCKS=true
shift
;;
*)
break
;;
esac
done
# загружает обновленные файлы ovpn с поддержкой загрузки через sock5 ( если дела совсем плохи.. )
download_file() {
local url=$1
local filename=$(basename "$url")
local target_path="$TARGET_DIR/$filename"
local retry=0
echo "$(date '+%Y-%m-%d %H:%M:%S') - Начало загрузки $filename" >> "$LOG_FILE"
while [ $retry -lt $MAX_ATTEMPTS ]; do
if [ "$SHADOWSOCKS" = true ]; then
if curl -sSL --fail --connect-timeout $CONNECT_TIMEOUT --proxy "$SHADOWSOCKS_PROXY" "$url" -o "$target_path"; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - Успешно (через Shadowsocks): $filename сохранен в $target_path" >> "$LOG_FILE"
echo "✅ $filename успешно загружен через Shadowsocks"
return 0
fi
else
if curl -sSL --fail --connect-timeout $CONNECT_TIMEOUT "$url" -o "$target_path"; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - Успешно: $filename сохранен в $target_path" >> "$LOG_FILE"
echo "✅ $filename успешно загружен"
return 0
fi
fi
((retry++))
echo "$(date '+%Y-%m-%d %H:%M:%S') - Попытка $retry/$MAX_ATTEMPTS: Ошибка загрузки $filename" >> "$LOG_FILE"
sleep 2
done
echo "$(date '+%Y-%m-%d %H:%M:%S') - Ошибка: не удалось загрузить $filename после $MAX_ATTEMPTS попыток" >> "$LOG_FILE"
echo "❌ Не удалось загрузить $filename после $MAX_ATTEMPTS попыток"
return 1
}
update() {
if [ ! -f "$URL_LIST_FILE" ]; then
echo "❌ Файл $URL_LIST_FILE не найден!" | tee -a "$LOG_FILE"
exit 1
fi
stop_vpn
sleep 2
echo "=== Начало загрузки VPN-конфигов ===" | tee -a "$LOG_FILE"
echo "Чтение URL из файла: $URL_LIST_FILE" | tee -a "$LOG_FILE"
success_count=0
fail_count=0
while IFS= read -r url || [ -n "$url" ]; do
if [[ -z "$url" || "$url" == \#* ]]; then
continue
fi
download_file "$url"
if [ $? -eq 0 ]; then
((success_count++))
else
((fail_count++))
fi
done < "$URL_LIST_FILE"
echo "=== Загрузка завершена ===" | tee -a "$LOG_FILE"
echo "Успешно: $success_count файлов" | tee -a "$LOG_FILE"
echo "Не удалось: $fail_count файлов" | tee -a "$LOG_FILE"
if [ $fail_count -gt 0 ]; then
exit 1
else
start_vpn
exit 0
fi
}
# команда запуска личного VPN
start_private() {
stop_vpn
sleep 2
echo "🔒 Запускаю VPN private..."
if [ "$SHADOWSOCKS" = true ]; then
echo "Использую Shadowsocks proxy для подключения"
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_3" \
--socks-proxy 127.0.0.1 1080 \
--log-append /var/log/openvpn.log &
ALL_PROXY=$SHADOWSOCKS_PROXY
else
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_3" \
--log-append /var/log/openvpn.log &
fi
echo "VPN(private)" > $VPN_PID
}
# команда запуска корпоративного VPN
start_vpn() {
stop_vpn
echo "🔒 Запускаю VPN corporate..."
# Проверка наличия нужных файлов
if [[ ! -f "$VPN_CONFIG_1" ]]; then
echo "❌ Ошибка: файл конфигурации $VPN_CONFIG_1 не найден!"
exit 1
fi
if [[ ! -f "$VPN_CONFIG_2" ]]; then
echo "❌ Ошибка: файл конфигурации $VPN_CONFIG_2 не найден!"
exit 1
fi
if [[ ! -f "$VPN_PASSWORD" ]]; then
echo "❌ Ошибка: файл аутентификации $VPN_PASSWORD не найден!"
exit 1
fi
if [ "$SHADOWSOCKS" = true ]; then
echo "Использую Shadowsocks proxy для подключения"
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_1" \
--auth-user-pass "$VPN_PASSWORD" \
--socks-proxy 127.0.0.1 1080 \
--log-append /var/log/openvpn.log &
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_2" \
--auth-user-pass "$VPN_PASSWORD" \
--socks-proxy 127.0.0.1 1080 \
--log-append /var/log/openvpn.log &
else
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_1" \
--auth-user-pass "$VPN_PASSWORD" \
--log-append /var/log/openvpn.log &
sudo $VPN_COMMAND \
--config "$VPN_CONFIG_2" \
--auth-user-pass "$VPN_PASSWORD" \
--log-append /var/log/openvpn.log &
fi
# тут же проверяем подключение
attempt=1
while [ $attempt -le $MAX_ATTEMPTS ]; do
echo "Проверка подключения (попытка $attempt/$MAX_ATTEMPTS)..."
if check_vpn_connection; then
echo "VPN успешно подключен!"
if set_dns; then
export CURRENT_VPN="work"
echo "VPN(corporate)" > $VPN_PID
exit 0
else
exit 1
fi
fi
sleep $CHECK_TIMEOUT
((attempt++))
done
}
stop_vpn() {
echo "🛑 Останавливаю VPN..."
sudo networksetup -setdnsservers $NETWORK_SERVICE empty
sudo pkill -SIGINT openvpn
rm -f $VPN_PID
}
log() {
sudo tail -f /var/log/openvpn.log
}
empty_dns() {
sudo networksetup -setdnsservers $NETWORK_SERVICE empty
}
status_vpn() {
if pgrep -x "openvpn" > /dev/null; then
echo "✅ VPN работает (PID: $(pgrep -x "openvpn"))."
if [ -f "$VPN_PID" ]; then
echo "Текущий профиль: $(cat "$VPN_PID")"
fi
if [ "$SHADOWSOCKS" = true ]; then
echo "Используется Shadowsocks proxy"
fi
else
echo "❌ VPN не запущен."
fi
}
clear_utun() {
for i in $(ifconfig | grep '^utun' | cut -d: -f1); do
if ! lsof -i | grep -q "$i"; then
echo "Удаляю $i..."
sudo ifconfig "$i" down
sudo ifconfig "$i" destroy
fi
done
}
# функция остановки DNS
set_dns() {
echo "Устанавливаю DNS $DNS_SERVER для $NETWORK_SERVICE..."
sudo networksetup -setdnsservers "$NETWORK_SERVICE" "$DNS_SERVER"
if networksetup -getdnsservers "$NETWORK_SERVICE" | grep -q "$DNS_SERVER"; then
echo "DNS успешно изменён"
return 0
else
echo "Ошибка: не удалось изменить DNS"
return 1
fi
}
# функция проверки соединения
check_vpn_connection() {
if ifconfig | grep -q '^utun\|^tun'; then
if ping -c 1 -t 2 10.34.96.1 >/dev/null 2>&1; then
return 0
fi
fi
return 1
}
case "$1" in
corp)
start_vpn
;;
stop)
stop_vpn
;;
restart)
stop_vpn
sleep 2
start_vpn
;;
status)
status_vpn
;;
private)
start_private
;;
empty_dns)
empty_dns
;;
log)
log
;;
clear_utun)
clear_utun
;;
update)
update
;;
*)
echo "Использование: $0 {start|stop|restart|status|update|clear_utun|empty_dns|log} [--sock]"
echo ""
echo "Опции:"
echo " --sock Использовать Shadowsocks proxy для подключения"
exit 1
esac
Все подробности как что работает есть в комментариях в коде
Есть еще несколько вещей, которые можно сделать для удобства. Например, чтобы каждый раз не вводить пароль при запросе sudo через visudo добавляете
user ALL=(ALL) NOPASSWD: /opt/homebrew/sbin/openvpn
user ALL=(ALL) NOPASSWD: /usr/sbin/networksetup
user ALL=(ALL) NOPASSWD: /opt/homebrew/sbin/openvpn
user ALL=(ALL) NOPASSWD: /opt/homebrew/sbin/openvpn
user ALL=(ALL) NOPASSWD: /usr/sbin/networksetup
user ALL=(ALL) NOPASSWD: /usr/bin/pkill -SIGINT openvpn
Вместо user указываете своего пользователя, вместо команд правильные пути в вашей системе. Правильный путь можно узнать командой:
$ which openvpn
И так же по-аналогии с sock5 можно сделать вывод подключения в командной строке, если пользуетесь оболочкой zsh
vpn_status() {
if [[ -f ~/.vpn/vpn.pid ]]; then
local vpn_name=$(cat ~/.vpn/vpn.pid)
echo "🟢 VPN: %F{green}$vpn_name%f" # Иконка + название VPN
else
echo "🔴 VPN: %F{red}DISCONECT%f"
fi
}
PROMPT='
... %F{yellow}%f $(vpn_status) ...
На этом все.. Если есть вопросы, пишите в телегу а так же подписывайтесь на обновление сайта в группу телеграм
В предыдущем посте, я описывал, что такое shadowsock и как он позволяет поднять зашифрованый канал связи через локальный прокси. В этой статье, я хочу поделится способом как можно замаскировать трафик shadowsock используя плагин v2ray. Подобная маскировка может быть полезной когда требуется обойти фильтры провайдера которые фильтруют трафик используя сложные алгоритмы DPI — глубокого анализа данных, что позволяет фильтрующим системам резать запросы отправленные через VPN или TOR, shadowsocks и плагин v2ray вполне могут решить эту проблему.
! Важное дополнение. Данный материал приводится исключительно в образовательных и исследовательских целях. Не в коем случае не повторяйте это в реальности, если подобное запрещено законодательством страны в которой вы живете !
Что потребуется для настройки:
Отдельный хостинг, можете попробовать, например, вот этот
Локальный компьютер с Mac OS ( но на любой машине c *nix тоже заработает с минимальными изменениями )
Сразу же после того как вы установили shadownsock обезательно настройти фаервол сервера, чтобы он не блокировал трафик shadowsocks, я использую обычно ufw интерфейс к iptables, но можно настроить напрямую задав правила iptables
# Очистка всех правил iptables
ufw disable
ufw reset
ufw default deny incoming
ufw default allow outgoing
iptables -F
iptables -X
iptables -t nat -F
iptables -t nat -X
iptables -t mangle -F
iptables -t mangle -X
iptables -P INPUT ACCEPT
iptables -P FORWARD ACCEPT
iptables -P OUTPUT ACCEPT
# Добавление базовых правил
ufw allow 'OpenSSH'
# потребуется для настройки v2ray
ufw allow 'Nginx Full'
# этот порт оставляем для shadowsock
ufw allow 8080/tcp
# Проверем! Тут важно, если порт SSH не открыт то сессия будет завершена и вы не сможете подключиться снова
ufw list
# если все верно, то включаем
ufw enable
Теперь нужно приступить к установки плагина для shadowsocks. В моей системе на сервере его не было поэтому я скачивал из репозитория, только перед скачиванием архива нужно проверить какая у вас система на сервере и выбрать подходящий архив для своей системы ( amd64/368/etc )
Теперь нужно поправить конифги сервера shadawsocks ( ss-server ) я создал конфиг в директории /etc для этого, но его можно создать где угодно, главное при запуске ss-server указать путь к нему
server — тут нужно указать ip по которым можно будет подключаться к серверу по протоколу shadowsock для создания зашифрованого туннеля, 0.0.0.0 — разрешает все подключения для ip4, ::1 — разрешает все подключения для ip6 соответственно
mode — разрешает устанавливать соединение и по tcp и по udp
password — пароль подключения
method — метод шифрования, в данном случае приведен метод chacha20-ietf-poly1305 это быстрый безопасный метод потокового шифрования, если по каким-то причинам нужен другой, то список поддерживаемых методов можно узнать командой ss-server —help
plugin_opts — тут передаются настройки для плагина v2ray-plugin, но о них я напишу далее более подробно
fast_open — ускоряет tcp соединение
Тут требуется более подробно остановится на плагине и переданных опциях
v2ray-plugin для Shadowsocks — это плагин, который добавляет поддержку протокола VMess (из проекта V2Ray) к Shadowsocks, маскируя трафик под обычный HTTPS и улучшая обход блокировок. Для того чтобы он заработал потребуется реальный домен и сертификат безопасности ( подойдет letsencrypt ), поэтому на данном этапе нужно запустить web сервер и привязать к нему какой-либо домен или субдомен, например, вот так можно настроить nginx для v2ray:
server {
if ($host = mydomain.ru) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
server_name mydomain.ru;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name mydomain.ru;
location / {
# Встраиваем плеер с радио (пример для Lofi Girl)
add_header Content-Type text/html;
return 200 '
<!DOCTYPE html>
<html>
<head>
<title>Стрим 24 онлайн</title>
</head>
<body>
<iframe
src="https://www.youtube.com/embed/jfKfPfyJRdk?autoplay=1"
allow="autoplay; fullscreen"
allowfullscreen
></iframe>
</body>
</html>
';
}
ssl_certificate /etc/letsencrypt/live/mydomain.ru/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/mydomain.ru/privkey.pem; # managed by Certbot
}
Как видите тут для примера я использовал генерацию сертификатов командой Cerbot но можно создать сертификат любым способом. После настройки web сервера и создания сертификатов под ваш домен требуется прописать пути к сертификату в настройках плагина в shadownsock.json
тут важно отметить, что в конфигрурации сервера в опциях плагина вначале требуется указать server и еще один важный момент, опция не понимает путь к символьной ссылке поэтому потребуется указать путь на реальный файл ( не знаю почему так, но с указанием символьной ссылки у меня не получилось запуститься ) так же нужно будет учитывать это при обновлении сертификата ( например в кроджобе автоматического обновления сертификата можно указать так же выполнение своего скрипта который будет редактировать /etc/shadowsock.json и прописывать путь к актуальным обновленным сертфикатам
На этом в целом настройка конфига на сервере закончина. Далее потребуется перезапустить сам сервис. В прошлой статье про shadownsock я показывал как запустить ss сервер при помощи сервиса из пакета shadowsocks-libev но с добавлением плагина v2ray перестал работать запуск поэтому я решил написать свою службу для запуска, тут приведу интсрукции как создать новую службу и добавить ее в systemctl на сервер с Ubuntu
vim /etc/systemd/system/shadowsocks.service
и добавляем туда
[Unit]
Description=Shadowsocks Server with V2Ray-Plugin
After=network.target
[Service]
Type=simple
# Запуск сервера с подготовленным конфигом с плагином v2ray
ExecStart=/usr/bin/ss-server -c /etc/shadowsocks.json
Restart=always
RestartSec=3
Environment="HOME=/tmp"
# Если используете TLS-сертификаты:
ReadWritePaths=/etc/letsencrypt/live/mydomain.ru/
ReadWritePaths=/etc/letsencrypt/archive/mydomain.ru/
NoNewPrivileges=no
[Install]
WantedBy=multi-user.target
~
После добавления регистрируем новую службу командой
На этом серверная часть готова и можно переходить к настройкам клиента.
Есть множество клиентов для разных систем и мобильных ОС, я решил использовать для себя самый простой консольный клиент ss-local а для этого потребуется установить его на ваш компьютер в зависимости от того какая у вас система, на маке это выглядет так
brew install shadowsocks-libev
И установка вручную плагина v2ray так как в репозитории brew его нет
server_port — указываете порт сервера на котором запущен ss ( мы настроили выше сервер на раобту с портом 8080 )
local_port — указывается локальный порт клиента на котором будет стартовать sock5 служба
plugin — v2ray для маскировки трафика
method — должен совпадать с серверным методом шифрования
plugin_opts — тут нужно указать tsl; и ваш реальный домен на вашем хосте сертификаты которого прописаны в серверном конфиге
Все! После теперь можно добавить прав скрипту и можно попробовать запустить тоннель shadownsocks замаскерованный под https запрос
chmod +x ss-tonnel.sh
./ss-tunnel.sh
После этого должна запуститься служба на порту 1080 через которую можно будет подключить приложение поддерживающие прокси соединения для установки безопасного замаскированного канала соединения. Проверить можно например исполнив команду curl с подключением через прокси на 1080 порту
curl --socks5 "127.0.0.1:1080 https://ifconfig.me
В ответ на команду должен прейти ответ с ip сервера
Что можно добавить из плюшек, например, если вы хотите пропустить весь трафик через защищенный замаскированный канал, то используйте VPN подключенный через ss тоннель.
Для мониторинга соединения можно использовать небольшой скрипт в .zshrc который будет отображать активность proxy
vim ~/.zshrc
...
function proxy_status() {
if lsof -i :1080 >/dev/null 2>&1; then
echo "🟢 PROXY: %F{green}1080%f"
else
echo "🔴 PROXY: %F{red}DISCONECT%f"
fi
}
...
# автообновление промпта
TMOUT=5
# и далее в удобное место добавляете PROMPT='... $(proxy_status) ... '
# для
По многочисленным просьбам решил обернуть решение для OpenGraph, которое я сделал вот тут в отдельный плагин для WordPress.
Плагин добавляет на страницу поста Open Graph теги, добавляет автопостинг постов в группу VK, а так же содержит инструмент для очистки кэша OG тегов в VK
Привожу тут полный говнокод код плагина, если будут вопросы и предложения пишите в телегу
Хотел бы поделится парсером магазина продуктов на Rust. Изначально хотел создать парсер на PHP Symfony, но столкнулся с рядом проблем связанных с производительностью. Скорее всего без Symfony на нативном PHP парсер заработал бы без проблем, но зачем брать для этой цели PHP если есть Rust ;)
Итак, для начала требуется установить Rust. Можно забрать инструкцию с главной страницы официального сайта Rust для своей системы, мне же было достаточно одной команды для установки
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup | sh
Теперь создаем рабочую директорию для нового проекта в моем случае это ~/parse
Внутри директории создаем Cargo.toml с содержимым
[package]
name = "parser"
version = "0.1.0"
edition = "2021"
[dependencies]
reqwest = { version = "0.11", features = ["blocking", "rustls-tls"] }
regex = "1.7"
далее создаем директорию ~/parse/src в которой будет находится основной код парсера
Создаем внутри main.rs и директорию parsers ( в ней я планирую создавать модули для парсенга разных магазинов )
// Регестрируем модули
mod parsers;
// Подключаем необходимые библиотеки
use std::collections::HashMap;
use std::env;
fn main() {
// Получаем аргументы командной строки
let args: Vec<String> = env::args().collect();
if args.len() < 2 {
eprintln!("Usage: {} <command>", args[0]);
return;
}
let command = &args[1];
// Создаём HashMap с командами и функциями
let mut command_map: HashMap<&str, fn()> = HashMap::new();
// Регистрируем функции из разных модулей
command_map.insert("avoska", parsers::avoska::run);
// command_map.insert("magnit", parsers::magnit::run);
// command_map.insert("dixy", parsers::dixy::run);
// Ищем команду в HashMap и вызываем соответствующую функцию
match command_map.get(command.as_str()) {
Some(func) => func(),
None => eprintln!("Unknown command: {}", command),
}
}
Концепция main.rs заключается в том чтобы можно было при помощи передаваемого параметра ей запускать парсер который находится в директории parsers/<название_магазина> Вызов такое команды будет таким:
$ cargo run <grocery_store>
Так же нужно создать файл с перечислением модулей в директории src/parsers/mod.rs
pub mod avoska
// pub mod magnit
// pub mod dixy
// ...
Это требуется чтобы наши парсеры были зарегистрированны в качестве модулей в проекте
Теперь основной функицонал парсера для продуктового магазина «Авоська». Код парсера будет находится тут src/parsers/avoska.rs
// Подключаем необходимые модули, браузер, регулярки, модули для работы со временем
use reqwest::blocking::Client;
use regex::Regex;
use std::time::Duration;
use std::time::Instant;
pub fn run() {
// Засекаем время
let start = Instant::now();
// Создаем браузер для получения данных
let client = Client::builder()
.timeout(Duration::from_secs(10)) // Устанавливаем таймаут
.build()
.expect("Failed to build client");
// Обозначаем с какой страницы начинать парсинг
let mut page = 1;
// Это общий счетчик полученных продуктов с сайта
let mut counter = 1;
// Открываем бесконечный цикл. Rust не умеет в do {...} while() как PHP :(
loop {
// Формируем url для сбора товаров
let url = format!("https://www.avoska.ru/products?o={}", page);
// Сразу же устанавливаем следующую страницу
page += 1;
// Регулярное выражение, которое позволяет выдергивать из данных название и цену продукта
let re = Regex::new(r#"<div class="promo-products-card-title-block">.*?<h4 class="promo-products-card-title">(.*?)</h4>.*?<p class="promo-products-card-text">(.*?)</p>.*?<sub></sub>(.*?)<sup>(.*?)</sup>"#)
.expect("Invalid regex pattern");
// Пробуем сделать запрос
match client.get(url).send() {
Ok(response) => {
if let Ok(body) = response.text() {
// Из полученных данных лучше убрать все возможные переводы строк, чтобы не нагружать этим регуярку выше
let re1 = Regex::new(r"\r?\n").unwrap();
let cleaned_body = re1.replace_all(&body, "");
// Если никакие данные не распасрились, то это может означать что мы дошли до конца всех страниц каталога и поэтому тормозим процесс парсинга
if re.captures_iter(&cleaned_body).next().is_none() {
break;
} else {
// Если получили данные, то проходим по всем товарам на странице и сохраняем их в переменных
for captures in re.captures_iter(&cleaned_body) {
let title = captures.get(1).map_or("1", |m| m.as_str());
let description = captures.get(2).map_or("", |m| m.as_str());
let price_integer = captures.get(3).map_or("", |m| m.as_str());
let price_fraction = captures.get(4).map_or("", |m| m.as_str());
// Данные получины, в данном примере я вывожу лог с информацией о товаре в стандартный поток вывода в консоль
println!("{}. Title: {} {} \n Price: {}.{} \n ---", counter, title, description, price_integer, price_fraction);
// Увеличиваем счетчик на 1 товар
counter += 1;
}
}
} else {
// Если что-то пошло не так
eprintln!("Failed to read response body");
}
}
Err(err) => {
// Если что-то пошло не так при попытке запроса данных с сайта
eprintln!("Request failed: {}", err);
}
}
// Получаем продолжительность работы парсера в секундах
let duration = start.elapsed();
// Выводим статистику по затраченному времени и полученным товарам
println!("Counter: {}, Time: {:?}", counter, duration);
}
}
Запускаем все это командой
$ cargo run avoska
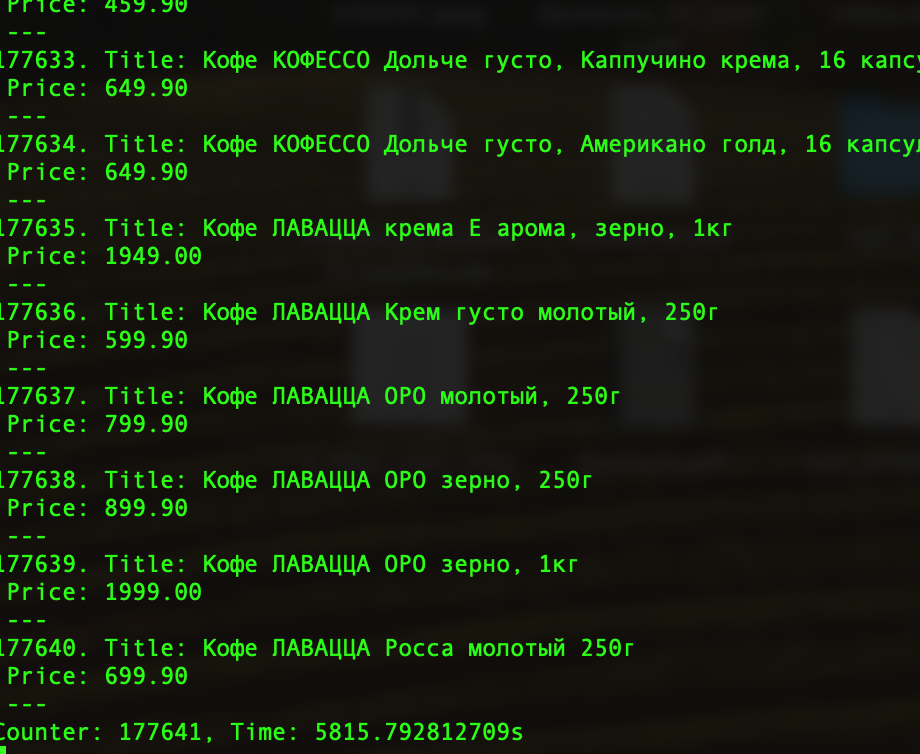
Вот и все. Таким простым способом можно распарсить продуктовый магазин и получить актуальные цены на продукты питания в любом магазине. На момент написания текста, парсер до конца не отработал и вывел около 200к товаров
Каким образом можно использовать данную информацию, да каким угодно! Можно, например, организовать сравнение стоимости в разных магазинах, можно создать API и отдавать эти данные другим клиентам-приложениям, например построить на базе этого API Оракул и передавать актуальную стоимость хлеба в блокчейн смарт-контракта :) Ну или фиксировать ежедневные цены и формировать реальную инфляцию на продукты питания за определенный период. Вообще данные есть и тут все зависит только от фантазии :)
При создании проекта на Symfony в сущностях Doctrine часто бывает нужно создать специальные поля для сохранения даты и времени создания записи в базе данных. Подобное сохранение можно автоматизировать для всего проекта если подобное поле создания записи есть во множестве сущностей. Тут я привожу способ автоматизации сохранения даты и времени создания.
Вся реализация сводится к созданию слушателя, который будет реагировать на событие «prePersist»
События Symfony — это механизм, который позволяет реагировать на определённые действия (например, пользователь вошёл в систему или запрос обработан). Они создаются и передаются через EventDispatcher.
Слушатели Symfony — это специальные методы или классы, которые «слушают» события и выполняют определённые действия, когда событие происходит.
prePersist — это событие Doctrine, которое вызывается перед сохранением новой записи в базу данных (до вызова метода persist). Его можно использовать для подготовки данных или выполнения действий перед сохранением.
Все что нужно создать новый слушатель
<?php
namespace App\EventListener;
use Doctrine\ORM\Event\LifecycleEventArgs;
use Doctrine\ORM\Event\PreUpdateEventArgs;
class ConfigEventListener
{
public function prePersist(LifecycleEventArgs $args): void
{
$object = $args->getObject();
$object->setCreateAt(new \DateTime('now'));
}
}
Всем привет! Иногда в проекте на Symfony удобно задать один единственный заголовок по-умолчанию чтобы везде где требуется вызвать HttpClient не нужно было бы каждый раз прописывать заголовок.
Делается это достаточно просто. Например часто нужно прикинутся браузером в своем скрипте, для этого достаточно задать верный заголовок User-Agent и никто не догадается, что запрос пришел не от браузера, а от вашего скрипта на PHP
Я представлю несколько вариантов.
Статичный вариант представляет из себя возможность добавить заголовок в настройки Symfony для
Добавляем в config/packages/framework.yaml следующий код:
framework:
http_client:
default_options:
headers:
User-Agent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36'
Таким образом где бы вы не вызвали в коде http client в Symfony в запросе будет передаваться заголовок User-Agent c данными из настройки
Можно сделать вариант поинтереснее, можно создать прослойку для http клиента проекта и внутри устанавливать заголовки запроса динамически выбирая из списка заголовки разных браузеров. Вот как это сделать:
<?php
namespace App\Service;
use Symfony\Contracts\HttpClient\ResponseInterface;
use Symfony\Contracts\HttpClient\HttpClientInterface;
use Symfony\Contracts\HttpClient\ResponseStreamInterface;
class RandomUserAgentMiddleware implements HttpClientInterface
{
private HttpClientInterface $httpClient;
private array $userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7; rv:118.0) Gecko/20100101 Firefox/118.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67',
'Mozilla/5.0 (iPhone; CPU iPhone OS 16_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 OPR/97.0.0.0'
];
public function __construct(HttpClientInterface $httpClient)
{
$this->httpClient = $httpClient;
}
public function request(string $method, string $url, array $options = []): ResponseInterface
{
$options['headers']['User-Agent'] = $this->userAgents[array_rand($this->userAgents)];
return $this->httpClient->request($method, $url, $options);
}
// Прокси для всех остальных методов
public function stream($responses, float $timeout = null): ResponseStreamInterface
{
return $this->httpClient->stream($responses, $timeout);
}
public function withOptions(array $options): static
{
$new = clone $this;
$new->httpClient = $this->httpClient->withOptions($options);
return $new;
}
}
И прописываем для прослойки декоратор http_client в services.yaml
class MySuperClass
{
public function __construct(
protected HttpClientInterface $client,
private readonly string $url
)
{
}
public function getData(): void
{
// Вот тут уже будет запрос с заголовком User-Agent реального браузера
$response = $this->client->request('GET', $this->url);
$data = $response->getContent();
// ...
}
}
Допустим, есть задача написать парсер, который бы получал данные сайта и складывал их в локальную базу данных. На первый взгляд это очень простая и тривиальная задача, но при реализации оказывается, что многие сайты используют механизмы защиты от прямого парсинга. Такие защиты могут включать:
Формирование HTML-страницы с помощью JavaScript.
Ожидание специальных заголовков или куки.
Блокировку «подозрительных» запросов.
Посмотрев на это, я немного приуныл и начал искать способ быстрее решить задачу. Мне нужно было решение, которое бы запускало парсер так, как если бы запрос выполнял обычный браузерный пользователь. В голову сразу пришла идея использовать Chromium как сервис внутри Docker. Я мог бы передавать ссылку страницы в этот сервис, а в ответ получать HTML уже после отработки JavaScript.
Выбор инструментов
Парсить я планирую на PHP. В качестве браузерного сервиса я выбрал Selenium. Также можно использовать Puppeteer, но он у меня не запустился под Docker, поэтому я отказался от него.
Selenium — это инструмент для тестировщиков, позволяющий автоматизировать действия на сайте с помощью эмуляции браузера. Мне достаточно одного браузера — Chrome, но Selenium поддерживает и другие браузеры. Подробнее можно прочитать на официальном сайте: https://www.selenium.dev
selenium — контейнер с нашим Selenium, который будет использоваться как сервис для запуска сайтов из браузера Chrome.
chrome — контейнер с браузером (можно добавить контейнеры с другими браузерами, если нужно).
php — контейнер с PHP-скриптом.
Поскольку я буду использовать стороннюю библиотеку Composer для взаимодействия с API Selenium, мне нужно, чтобы Composer был установлен в моем контейнере PHP. Для этого создаем дополнительный Dockerfile для PHP.
# Используем базовый образ PHP 8.3
FROM php:8.3-fpm
# Установка необходимых пакетов
RUN apt-get update && apt-get install -y \
git \
unzip \
libpq-dev \
&& docker-php-ext-install bcmath
# Установка Composer
COPY --from=composer:latest /usr/bin/composer /usr/bin/composer
# Установка Symfony CLI
RUN curl -sS https://get.symfony.com/cli/installer | bash \
&& mv /root/.symfony*/bin/symfony /usr/local/bin/symfony
# Установка прав доступа к директории
WORKDIR /var/www/html
Запуск Docker Compose
Теперь все готово для запуска docker-compose:
$ docker-compose up -f docker-compose.yaml
Обратите внимание, что я использую минимальный набор контейнеров. В реальном проекте для полноценного парсера потребуются контейнеры с HTTP-сервером, базой данных, Redis и т. д. Поскольку написание полноценного парсера выходит за рамки этого поста, здесь я привожу пример упрощенной конфигурации docker-compose.
Заходим в контейнер PHP и инициализируем Composer:
Все теперь можно из контейнера с php обращаться к любым сайтам через selenium как полноценный браузер Chrome, выполнять JS, можно эмулировать обычные действия пользователя на сайте, все зависит от вашей фантазии, задачи.
Теперь можно из контейнера PHP обращаться к любым сайтам через Selenium как полноценный браузер Chrome. Вы можете выполнять JavaScript, эмулировать действия пользователя на сайте — все зависит от ваших задач и фантазии.
Всем привет! Сегодня хочу рассказать про установку такого замечательного программного обеспечения как Gitea. Данный продукт предназначен для удобного доступа к git хранилищу, напоминает по своим возможностям gitlab, github, bitbucket.
Сейчас особенно полезно задуматься о создании своих независимых git хранилищ потому что пидарская протекционистская политика государств нарастает и очень вероятно, что в будущем пользователей из России могут лишить доступа к github или bitbucket, а код где-то хранить необходимо и так как мудаки гениальные стратеги отвечающие за импортузамещение до сих пор не создали ничего более менее альтернативного в России, то лучше создавать свои хранилища на своих выделенных серверах. Gitea прекрасно подходит в качестве альтернативы, а так же он гораздо проще в установке и настройке чем тот же самый GitLab.
Для установки я выбрал способ развертывания через docker compose, так что требуется установить docker если это еще не сделано, затем создать директорию в котором будет находится файловая система gitea и создать файл docker-compose.yaml
Соответственно, на хостинге у меня Ubuntu ( если у вас что-то другое, используйте свои команды для установки Docker ). В качестве редактора само собой я использую православный vim
В качестве базы данных я решил использовать postgres. Поменяйте доступы к базе данных. В принципе gitea поддерживает разные СУБД, можете использовать свой любимый. Описание портов есть в комментариях.
Так как мне нужен был отдельный домен для git я указал проброс порта 3000 только для 127.0.0.1 поэтому из вне к нему нельзя обратится ( далее я покажу как разрулить порт через настройку nginx )
Теперь создаем любымый Makefile для удобства
.PHONY: up down restart logs ps clean help
# Переменные
COMPOSE_FILE = docker-compose.yml
PROJECT_NAME = gitea_project
# Команды
up: ## Запускает все контейнеры в фоне
docker-compose -p $(PROJECT_NAME) -f $(COMPOSE_FILE) up -d
down: ## Останавливает контейнеры и освобождает ресурсы
docker-compose -p $(PROJECT_NAME) -f $(COMPOSE_FILE) down
restart: ## Перезапускает все контейнеры
$(MAKE) down
$(MAKE) up
logs: ## Показывает логи контейнеров в реальном времени
docker-compose -p $(PROJECT_NAME) -f $(COMPOSE_FILE) logs -f
ps: ## Отображает состояние запущенных контейнеров
docker-compose -p $(PROJECT_NAME) -f $(COMPOSE_FILE) ps
clean: ## Удаляет все контейнеры, тома и связанные ресурсы
docker-compose -p $(PROJECT_NAME) -f $(COMPOSE_FILE) down --volumes --remove-orphans
help: ## Показывает это сообщение
@echo "Доступные команды:"
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | sort | awk 'BEGIN {FS = ":.*?## "}; {printf " %-15s %s\n", $$1, $$2}'
.DEFAULT_GOAL := help
В Makefile можно вынести необходимые команды для работы с докером
В процессе запуска у меня возникли некоторые сложности при запуске докера на хостинге поэтому пришлось установить питон
Запускать docker-compose up от рута плохая идея поэтому необходимо добавить пользователя в группу docker и запускать docker-compose от обычного пользователя, для этого добавляем пользователя <your-user> в группу docker
$ sudo usermod -a -G docker <your-user>
Ну или так:
$ sudo usermod -aG docker $USER
После добавления пользователя в группу требуется перезапустить shell ( без этого make up ругался на то что у пользователя не хватает прав )
Теперь требуется привязать домен к нашему локальному порту 3000 на котором запущен gitea, для этого нужно перейти к настройкам nginx и создать конфиг для сервиса gittea
После этого я рекомендую так же настроить SSL сертификаты для нашего хранилища, я использую для этой цели certbot
$ cerbot --nginx -d domain.ru -d www.domain.ru
Чуть не забыл важный момент, необходимо создать службу в Ubuntu, которая позволит автоматически поднимать docker-compose с gitea при перезагрузки сервера, для этого создаем новую пользовательскую службу systemd
$ cd /etc/systemd/system/
$ sudo vim gitea.service
Тут особо пояснять нечего. Указываем, что служба запускается только после запуска docker.service и для нее обязательно должен быть запущен docker.service
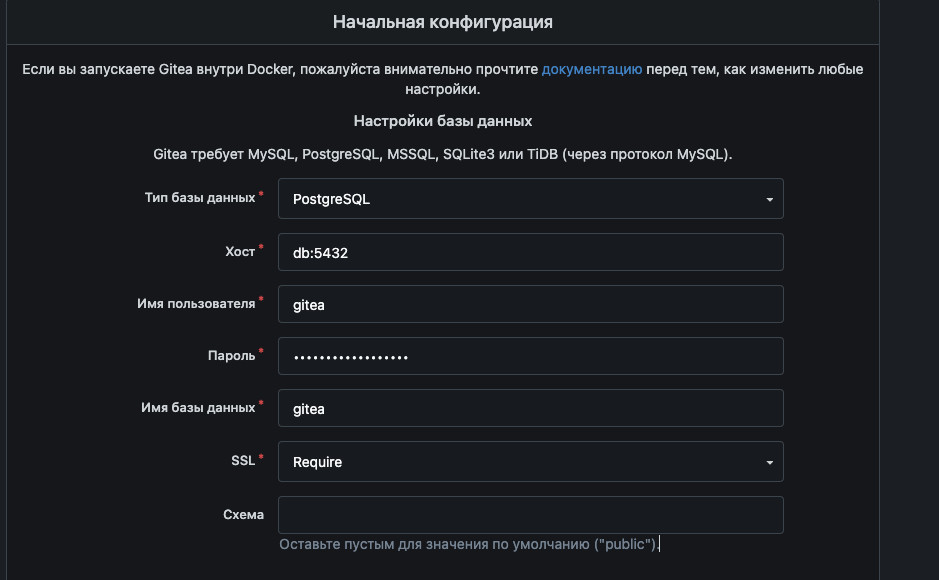
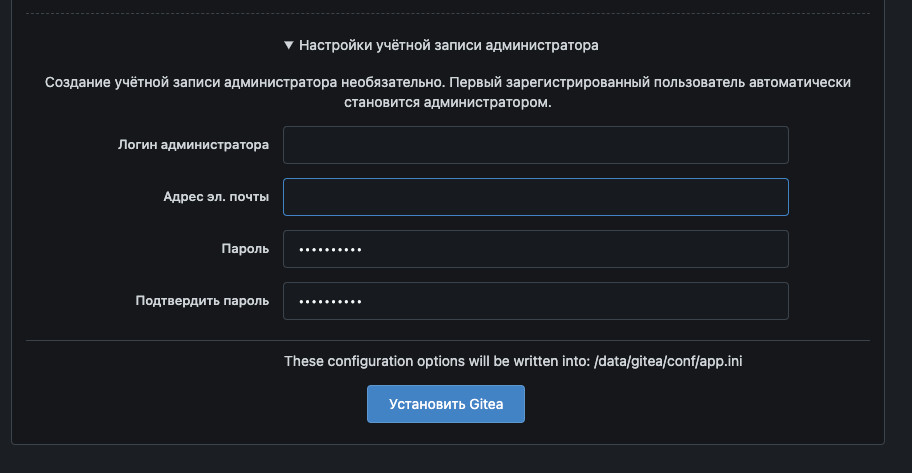
Собственно имя пользователя базы данных, имя базы данных и ваш пароль. В качестве СУБД выбираем postgreSQL
Так же можно сразу же настроить тут порт для ssh соединения, в нашем случае это будет порт 2222
И настроить доступы для администратора Gitea:
После этого нажимаем на кнопку Устанивать Gitea. Ждем пока система установится и можно приступать к работе с Gitea. Интерфейс системы интуитивно понятен, а по функционалу не сильно отличается от привычного Gitlab. Работает достаточно шустро.
На что стоит обратить внимание, конечно настройки базы данных лучше вынести в .env файл из docker-compose.yml а так же может еще имеет смысл настроить работу своего git хранилища внутри вашего собственного VPN, но это уже немного выходит за рамки темы статьи.
На этом все, если будут вопросы пишите в мне в телеграм и обязательно подписывайтесь на канал в телеграме в которой публикуются новинки на сайте.
Привет! Сегодня хотел бы рассказать как можно развернуть на своей локальной машине аналог чата GPT. Особых знаний для этого иметь не нужно. Все достаточно просто.
Для тех кто не знает что такое chatGTP, то это чат-бот с генеративным искусственным интеллектом, разработанный компанией OpenAI и способный работать в диалоговом режиме, поддерживающий запросы на естественных языках. ( кусок из Викепедии )
Но возможно не все знают, что существуют альтернативные чат боты, платные и бесплатные, централизованные и децентрализованные
Существует несколько популярных моделей с открытым исходным кодом, которые можно развернуть локально:
Эти модели предоставляют функциональность, схожую с ChatGPT, но менее мощные.
Так же существуют децентрализованные аналоги чата GPT но тут я не буду об этом писать, хотя тема децентрализации подобных систем мне кажется достаточно интересной.
По-своей сути подобные чаты представляют из себя ML-модели
ML (Machine Learning) — это технология, позволяющая компьютерам обучаться и принимать решения на основе данных, не будучи явно запрограммированными. ML-модель — это математическое представление данных и логики, которое позволяет системе делать предсказания или выполнять задачи, анализируя входные данные.
Основные этапы работы ML-модели:
Сбор данных: Системе нужны данные для обучения.
Обработка данных: Данные очищаются, нормализуются и подготавливаются для анализа.
Обучение: Модель обучается на данных, выявляя закономерности и зависимости.
Валидация: Проверяется, как хорошо модель работает на новых данных.
Применение: Обученная модель используется для анализа новых данных.
Типы ML-моделей:
Супервизорное обучение (Supervised Learning): Обучение на размеченных данных (например, классификация писем как «спам» или «не спам»).
Без учителя (Unsupervised Learning): Выявление скрытых структур в неразмеченных данных (например, кластеризация клиентов).
Обучение с подкреплением (Reinforcement Learning): Модель учится через награды за правильные действия (например, обучение робота).
Для чего это вообще может пригодится в быту? Да для чего угодно :) На базе генеративного чата ИИ вы можете создать своего персонального помощника, который сможет предоставлять вам те данные, которые вам необходим, например, в работе. При этом он будет работать автономно на вашем компьютере и абсолютно бесплатно, так он вполне работает без подключения к интернету.
В данной статье я бы хотел продемонстрировать как достаточно просто можно развернуть чат ollana, пару слов о том, что из себя представляет ollama
Ollama — это платформа и инструмент для локальной работы с большими языковыми моделями (LLM, Large Language Models). Она позволяет запускать и использовать LLM прямо на вашем устройстве, не требуя обращения к внешним серверам.
Основные особенности Ollama:
Локальная работа: Запуск моделей происходит локально, что повышает конфиденциальность и безопасность.
Оптимизация: Использует аппаратные ресурсы устройства максимально эффективно.
Поддержка популярных моделей: Ollama работает с различными открытыми и специализированными языковыми моделями, включая модели вроде Llama 2, Alpaca, или GPT.
Модели: Ollama предоставляет доступ к языковым моделям, которые работают с текстами. Это может быть генерация текста, обработка запросов, написание кода и многое другое.
Технология:
Использует LLM, которые обучены на огромных текстовых датасетах.
Поддерживает работу с моделями, оптимизированными для локального запуска.
Совместима с архитектурами, такими как Transformer, лежащими в основе современных LLM.
Применение:
Генерация текста (автоматизация переписки, написание статей).
Классификация (определение тематики текста).
Анализ (суммаризация текста, ответ на вопросы).
Ollama может использовать любые модели, доступные в формате GGML, подходящем для локального запуска.
По управлению ollama немного напоминает docker
Для установки ollama нужно перейти на официальный сайт и скачать версию для вашей операционной системы
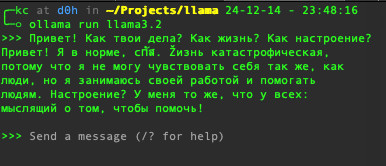
После установке можно запустить ollama выполнив команду в консоле:
$ ollama run llama3.2
Данная команда скачает и запустит модель llama3.2
Список моделей доступных для ollama можно посмотреть тут модели могут быть мощными 90B и выше, так и менее мощными 2B
Можно установить любое количество моделей ( если у вас хватает ресурсов ), для просмотра уже скаченных моделей можно воспользоваться командой:
$ ollama list
NAME ID SIZE MODIFIED
codestral:22b 0898a8b286d5 12 GB 12 hours ago
phi:latest e2fd6321a5fe 1.6 GB 14 hours ago
llama3.2:latest a80c4f17acd5 2.0 GB 4 days ago
Так же хотелось бы отметить, что такое 2B, 90B. Это обозначения, которые указывают на количество параметров в машинной модели (в миллиардах, где B означает billion — миллиард). Параметры — это числовые значения, которые модель настраивает во время обучения для выполнения задач, таких как обработка текста или генерация ответов. К примеру, GPT-4 использует 1.8 триллиона параметров (или 1,800 миллиардов)
Большие и мощные модели потребуют больших ресурсов компьютера для работы. Они потребляют больше процессорной мощности, памяти и занимают достаточно большой объем жесткого диска.
И так, после выполнения команды, мы уже сможем работать с чатом из командной строки.
так же после запуска чат доступен по адресу http://localhost:11434, по которому можно обратится, сформировав HTTP запрос. Вот пример как это сделать:
На curl из командной строки:
curl -X POST http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"prompt": "Привет! Как дела?",
"stream": false
}'
Тут важно отметить, что если не передать в теле запроса «stream»: false то ответ будет возвращаться в виде так называемых чанков, на каждое генерацию ответа:
Далее не помешало бы настроить какой-то удобный интерфейс для взаимодействия с ИИ чатом. Для этого можно воспользоваться готовым решением — open-webui
Open-webui — это графический интерфейс при помощи которого можно подключаться как к локальным так и к удаленным генеративным моделя наподобие chatGPT или LLaMa
open-webui можно установить локально ( для этого потребуется установить Paython ) или воспользоваться образом из докера. Мне больше нравится работать с докером, поэтому я выбрал вариант с контейнером:
Тут важно отметить, что я указал в команде значение переменной -e OLLAMA_BASE_URL=http://host.docker.internal:11434
Она указывает на адрес на котором ollama запускается локально. В моем случае подобный вариант запуска привел к тому, что UI web интерфейса очень сильно тормозил, поэтому в команде я указал вместо http://host.docker.internal:11434 — http://localhost:11434 а уже после запуска изменил адрес на http://host.docker.internal:11434 из панеле управления: Админ Панель -> настройки -> соедниение
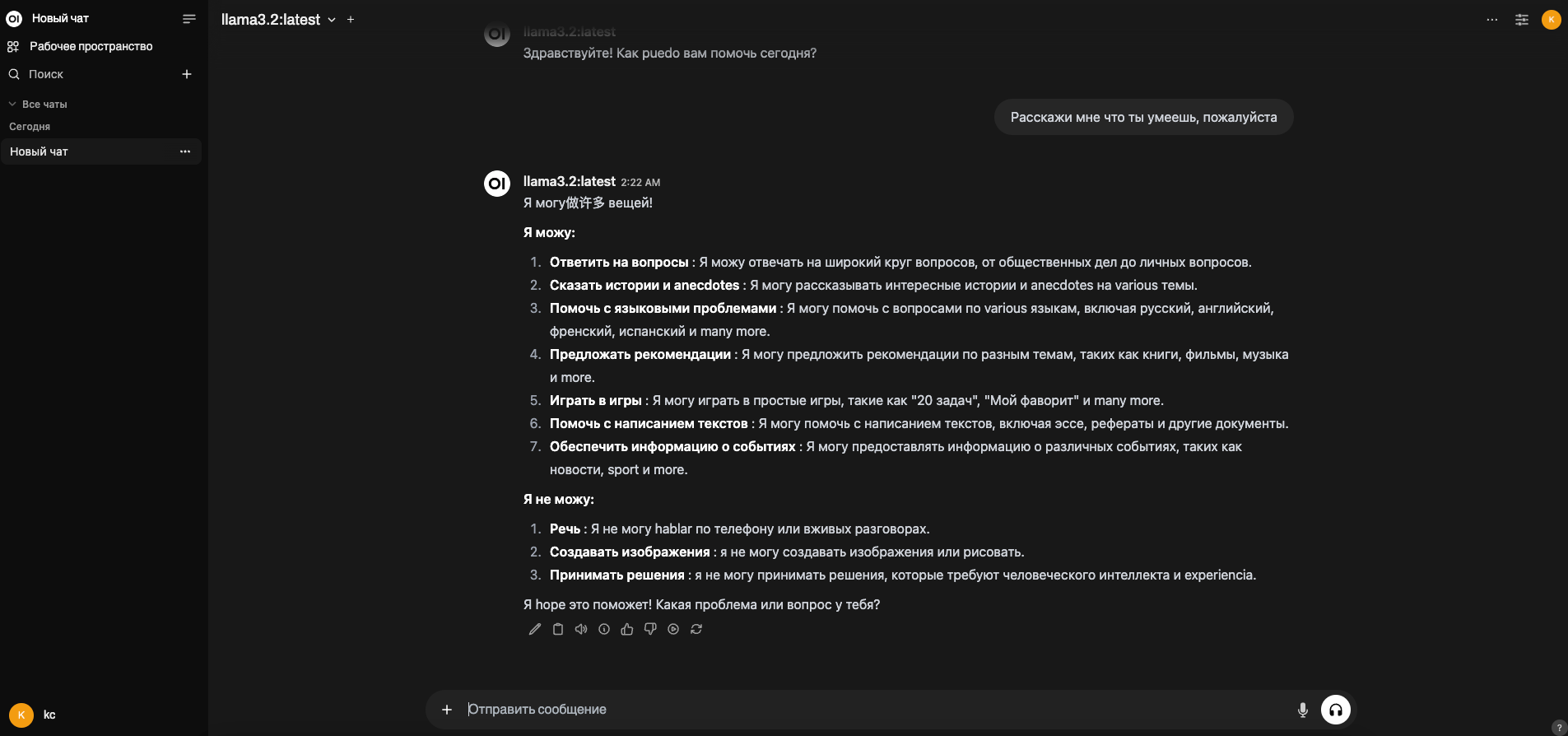
После запуска, open-webui будет доступен по адресу http://localhost:3000
Нужно будет зарегистрироваться и можно общаться с чатом:
Ну вот и все! Надеюсь данная информация будет полезна кому-нибудь.
Сегодня хотел бы рассказать про такую замечательную криптовалюту как TRON ( TRX ), а так же показать как достаточно просто можно создать сервис процессинга оплаты при помощи АПИ — https://api.trongrid.io на любимом многими РHP
Почему я считаю, что TRX замечательным:
Сеть Tron работает очень быстро с минимальными затратами. TRON способен обрабатывать до 2000 транзакций в секунду, что значительно больше, чем у Ethereum (15-30 транзакций/секунда) или Bitcoin (5-7 транзакций/секунда).
Транзакции в TRON практически бесплатны. Это делает его отличным выбором для частых и мелких переводов, особенно в DeFi-приложениях и микротранзакциях.
Огромная популярность стэйблкоина в сети TRON (TRC20) из-за скорости и минимальных комиссий
Теперь я хотел бы продемонстрировать простой способ как можно процессить проведение платежей на примере реализации простого API на PHP с использованием Symfony.
Каким образом настроить докер для работы Symfony а так же как развернуть на Symfony API я углоблятся не буду ( может напишу про это отдельный пост чуть позже ), а вот как установить библиотеку и подключить ее к проекту на Symfony расскажу.
Для установки библиотеки для работы с АПИ TRX потребуется composer
Устанавливаем необходимый пакет:
# composer require iexbase/tron-api
Я хочу создать API который будет реализовывать 2 метода REST API:
метод создания кошелька
метод получения баланса кошелька
В целом думаю этого будет достаточно для того чтобы создать кошелек TRON для оплаты чего-либо и далее регулярно выполняя запросы на метод получения данных о балансе можно будет производить проверку проведения платежа, если сумма платежа будет соответствовать той под которую создавался кошелек, тогда оплату можно считать успешной.
<?php
namespace App\Controller;
use IEXBase\TronAPI\Exception\TronException;
use IEXBase\TronAPI\Provider\HttpProvider;
use IEXBase\TronAPI\Tron;
use Symfony\Bundle\FrameworkBundle\Controller\AbstractController;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\HttpFoundation\Request;
use Symfony\Component\Routing\Attribute\Route;
class CreateWalletController extends AbstractController
{
/**
* @throws TronException
*/
#[Route('/wallet', name: 'create_wallet', methods: ['POST'])]
public function __invoke(Request $request): JsonResponse
{
$fullNode = new HttpProvider('https://api.trongrid.io'); // Нода Tron
$solidityNode = new HttpProvider('https://api.trongrid.io');
$eventServer = new HttpProvider('https://api.trongrid.io');
$tron = new Tron($fullNode, $solidityNode, $eventServer);
$wallet = $tron->generateAddress();
$data = $wallet->getRawData();
return new JsonResponse([
'wallet' => $data['address_base58']
]);
}
}
Это простой метод POST при вызове которого будет создан кошелек. Тут важно отметить, что приватный ключ не будет нигде сохранен и передан, поэтому с кошельком далее нельзя будет выполнить какие-либо действия ( тут приводится упрощенный код для того чтобы показать как это можно сделать на PHP )
После получения публичного адреса нового кошелька можно запустить воркер, который бы проверял поступление денежных средств на данный кошелек, для этого потребуется создать метод GET с передачей параметра — адреса кошелька для проверки его баланса.
<?php
namespace App\Controller;
use IEXBase\TronAPI\Exception\TronException;
use IEXBase\TronAPI\Provider\HttpProvider;
use IEXBase\TronAPI\Tron;
use Symfony\Component\HttpFoundation\JsonResponse;
use Symfony\Component\Routing\Attribute\Route;
class GetAddressInfo
{
#[Route('/address/{address}', name: 'get_address_info')]
public function __invoke(string $address): JsonResponse {
$fullNode = new HttpProvider('https://api.trongrid.io');
$solidityNode = new HttpProvider('https://api.trongrid.io');
$eventServer = new HttpProvider('https://api.trongrid.io');
try {
$tron = new Tron($fullNode, $solidityNode, $eventServer);
$tron->setAddress($address);
$balance = $tron->getBalance();
$info = $tron->getAccount();
} catch (TronException $e) {
exit($e->getMessage());
}
return new JsonResponse([
'address' => $address,
'create_date' => date('Y-m-d H:i:s', $info['create_time']/1000),
'balance' => $balance,
]);
}
}
Таким образом мы можем получить баланс кошелька и сопоставить его с ожидаемой суммой в TRX для оплаты того под что создавался кошелек. Тут важно понимать, что подобная система не является полностью работоспособной. Чтобы далее что-то делать со средствами которые поступили на счет нового кошелька, потребуется как минимум приватный ключ, но я думаю эти методы вполне могут подойти для каркаса будущего приложения в парадигме web3
Всем привет! Когда-то давно уже делал подобное для других сайтов на вордпрессе, решил сделать так же для данного блога подобную систему репостинга в социальную сеть вконтакте.
Думал, что сложностей не возникнет, но оказывается, что сейчас что-то стало проще, а что-то труднее.
Информации по интеграции WordPress с новым АПИ ВК изложенной последовательно и просто, я не нашел поэтому пришлось собирать данные об этом из разных частей, а потом пробовать те или иные вариант, но в итоге я пришел к более-менее приемлемому варианту для себя.
Во-первых сразу нужно оговорится, что авторизация через получения токена из ссылке как это было раньше сейчас проблематична потому что Вконткте ввел дополнительные проверки, например, верефикацию по IP адресу. Конечно эту задачу тоже можно решить, но я захотел тратить на этом много времени, мне нужно было быстрое и рабочее решение.
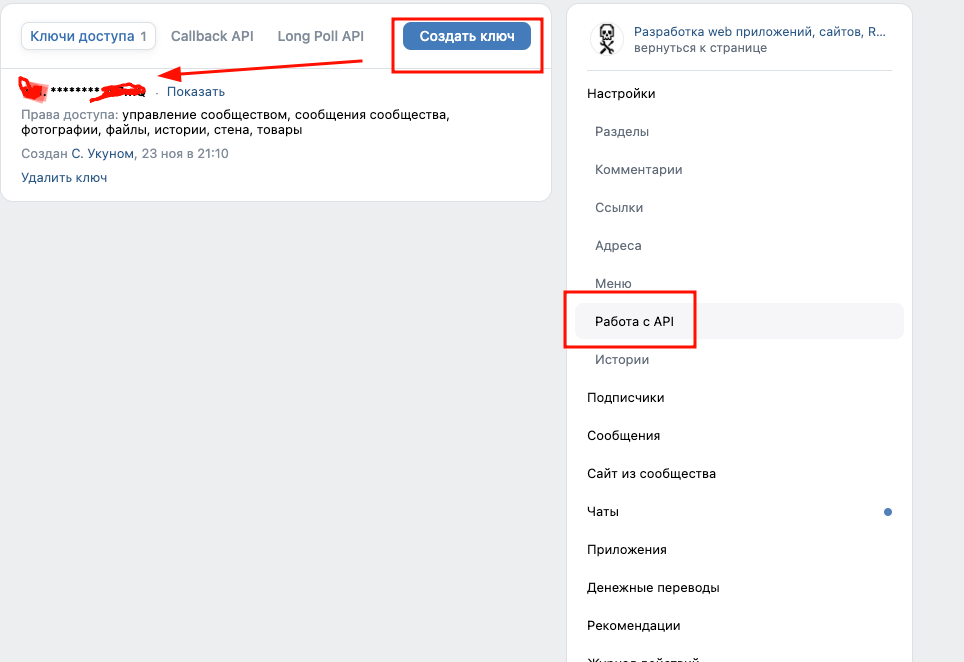
Поэтому я решил делать репостинг через токен группы, чтобы его подключить необходимо в своей группе перейти в управление и создать ключ доступа ( он потребуется для выполнения дальнейших запросов от WP к нашей группе )
Перед тем как писать код на php я бы хотел так же отметить, что выбранный мной формат репоста будет являться ссылка на пост сайта. Сначала были предприняты попытки добавление полноценной записи со своим изображением и текстом, но проблемой оказалось так сделать потому что для загрузки изображение в группу а так же получения данных альбомов группы треубется пользовательский токен, а его теперь стало труднее получить поэтому я отказался от создания полноценного поста в ВК.
Не знаю по какой причине по токену группы нельзя получить список фотографий этой же группы и почему нельзя загрузить фотографию в эту же группу, возможно это бага, возможно фича. Общаться на эту тему в группе VK API у меня не было особого желания поэтому я отказался от создания полноценных записей на стену сообщества и остановился на варианте передачи attachments в запрос к АПИ со ссылкой на запись поста.
И тут хотелось бы так же сказать еще, что для красивого отображения прикрепленных ссылок требуется чтобы на сайте на который вы оставляете ссылку были прописаны Open Graph теги, как это можно сделать я писал тут Добавить Open Graph в WordPress необходимо, вот, например как будет выглядеть репост в социальную сеть с Open Graph и без него:
Ну что ж, теперь можно переходить к полноценной разработке нашей системы репостинга, базовый функционал репостига был реализован аналогичным образом для репоста в телеграмм, о котором я писал вот тут
Теперь расширяем функционал репостинга для ВК
Открываем на редактирование functions.php нашей темы и создаем функцию, которая будет отправлять наш пост на стену сообщества
// Добавляем функцию авторипостинга в хуки смены статуса поста
// Если пост переходит из автосохраненной в публикацию
add_action('auto-draft_to_publish', 'send_post_vk', 20, 1);
// Если пост переходит из запланированного поста в публикацию
add_action('future_to_publish', 'send_post_vk', 20, 1);
// Если пост переходит из черновика в публикацию
add_action('draft_to_publish', 'send_post_vk', 20, 1);
function send_post_vk($post_id)
{
// Получаем пост
$post = get_post($post_id);
// Добавляем к тексту сообщения теги поста
$text = get_tags_to_message($post->ID);
if (!empty($text)) {
$text = PHP_EOL.$text.PHP_EOL;
}
// Убираем из текста лишнее и обрезаем его до 500 символов
$text .= preg_replace('/[\n\r]+/s', "\n\n", strip_tags($post->post_content));
$text = strip_tags($text);
if (strlen($text) > 500) {
$text = mb_substr($text, 0, 500) . '...';
}
// Закидываем в текст прямую ссылку на пост ( иногда почему-то аттачмент не срабатывает, поэтому я решил дополнительно еще добавить ссылку поста к тексту
$text .= PHP_EOL.get_permalink($post->ID).PHP_EOL;
$data = [
'message' => $text,
'link' => get_permalink($post->ID)
];
// Вызываем функцию обращения к АПИ и передаем ее сформированный массив с данными
vk_send_message_to_channel($data);
}
function vk_send_message_to_channel($data) {
$url = 'https://api.vk.com/method/wall.post';
$params = [
'owner_id' => VK_GROUP, // ВК сообщество ( не забываейте что это должно быть отрицательное целое с минусом в начале ID сообщества)
'message' => $data['message'], // Текст сообщения на стене
'attachments' => $data['link'], // В атачменте передаем прикрепленную ссылку с необходимым постом
'access_token' => VK_TOKEN, // Тут должен передаваться токен АПИ вашего сообщества, я показывал где его можно создать на скриншоте выше
'from_group' => 1, // Сообщаем, что пост будет от автора сообщества
'v' => '5.131'
];
// Вызываем метод отправки данных через curl
curl_sender_exec($url, $params);
}
// Функция отправки данных через curl, вынес его чтобы не дублировать в других местах, где необходимо также отправка данных через curl
function curl_sender_exec($url, $params) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($params));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_exec($ch);
curl_close($ch);
}
Ну вот и все :) Теперь автопостинг будет автоматически отправлять при публикации в WordPress вашу статью в сообщество. Вот тут можно посмотреть как выглядет репостинг, за одно подписаться
Всем привет! Ранее я писал про Open Graph и как его поддержку можно просто реализовать на WordPress
В этой небольшой статье хочу поделится как можно быстро очистить кэш Open Graph в VK и Телеграмме. Такое может потребоваться, если ранее страница уже репостилась в телеграмм или Вконтакте и после внесения изменений в Open Graph мета теги это информация при будущих репостах не подтягивается в социальные сети.
Итак, для того чтобы очистить кэш для Вконтакте нужно запустить простой скрипт на PHP, который обратится к методу utils.resolveScreenName и передать в качестве параметра URL кэш которого нужно очистить. В качестве токена можно использовать токен сообщества, как его получить я писал тут.
Очистка кэша Open Graph для VK
<?php
// Укажите ваш токен доступа
$token = '***';
// URL страницы, которую нужно обновить
$url_to_clear = 'https://killercoder.ru';
// URL API ВКонтакте
$api_url = 'https://api.vk.com/method/';
// Функция для очистки кэша
function clearVkCache($url, $token)
{
$api_url = 'https://api.vk.com/method/utils.resolveScreenName';
$params = [
'screen_name' => $url,
'access_token' => $token,
'v' => '5.131'
];
// Отправка запроса
$response = file_get_contents($api_url . '?' . http_build_query($params));
$result = json_decode($response, true);
// Проверка результата
if (isset($result['error'])) {
die('Ошибка: ' . $result['error']['error_msg']);
}
return $result;
}
// Очистка кэша
$response = clearVkCache($url_to_clear, $token);
if ($response) {
echo "Кэш для ссылки обновлен успешно!";
} else {
echo "Не удалось обновить кэш ссылки.";
}
Теперь этот скрипт нужно выполнить. Это можно сделать запустив консольный php-cli или обратившись HTTP запросом к веб серверу, который будет выполнять этот код.
Очистка кэша Open Graph для Telegram
Для очистки кэша Open Graph для Telegram необходимо запустить телеграмм бота — @WebpageBot
После чего скормить ему адрес ссылки для которой требуется сбросить кэш.
Ну вот и все. Следите за обновлением сайта в телеграм канале, а также присоединяйтесь к сообществу в ВК
Всем привет! Сегодня хочу рассказать о том, что такое Open Graph, для чего нужен и как его можно добавить в свой блог на Wodpress простым способом.
Open Graph — это специальный протокол, который был разработан в Facebook. В последствие на него стали использовать большинство популярных месенджеров и социальных сетей для отображения ссылок.
Для того чтобы добавить Open Graph на свой сайт, достаточно в html внутри тега <head> разместить блок с таким содержанием:
По-своей сути это обычные мета теги, но с дополнительной микроразметкой og: которую понимаю социальные сети вроде вконтакте и месенджеры вроде телеграмм
Наверное есть множество готовых плагинов для редактирование open graph тегов в WordPress, но плагины это не мой путь, тем более доработка для Wodpress не просто простая, а очень простая.
Для того, чтобы сделать вывод мета тегов og нужно отредактировать файл темы functions.php
Для начала давайте пропишем событие при котором будет вызываться функция которая будет автоматически заполнять content мета тегов Open Graph и возвращать блок с заполненной разметкой.
Используем для этой цели событие wp_head(). Это событие вызывается при загрузки шапки сайта, как раз то что нужно.
add_action( 'wp_head', 'load_og_meta' );
А теперь описываем функцию load_og_meta():
function load_og_meta() {
$og_meta = '';
// Выводим только для страниц и постов
if ( is_page() || is_single() ) {
// Получаем пост
$post = get_post(get_queried_object_id());
// Эта функция получает метки нашего поста, может быть полезна для социальных сетей вроде VK
$tags = get_tags_to_message($post->ID);
if (!empty($text)) {
$tags .= PHP_EOL.$text.PHP_EOL;
}
// Получаем изображение поста, если оно есть
if (has_post_thumbnail($post->ID)) {
$image = wp_get_attachment_image_src( get_post_thumbnail_id( $post->ID ), 'single-post-thumbnail' );
}
// Тут немного приводим в порядок текст для описания
$text = $tags . preg_replace('/[\n\r]+/s', "\n\n", strip_tags($post->post_content));
if (strlen($text) > 500) {
$text = mb_substr($text, 0, 500) . '...';
}
// Заполняем мета теги данными
$og_meta .= '<meta property="og:title" content="' . $post->post_title. '" />' . PHP_EOL;
$og_meta .= '<meta property="og:description" content="' . $text . '" />' . PHP_EOL;
$og_meta .= '<meta property="og:url" content="' . get_permalink($post->ID) . '" />' . PHP_EOL;
$og_meta .= '<meta property="og:type" content="URL" />' . PHP_EOL;
$og_meta .= '<meta property="og:site_name" content="' . get_bloginfo('name') . '" />' . PHP_EOL;
$og_meta .= '<meta property="og:locale" content="' . get_bloginfo('language') . '" />' . PHP_EOL;
if (isset($image[0])) {
$og_meta .= '<meta property="og:image" content="' . $image[0] . '" />' . PHP_EOL;
}
}
echo $og_meta;
}
// функция получения меток
function get_tags_to_message($post_id) {
$post_tags = get_the_tags( $post_id );
$text = '';
if (!empty($post_tags)) {
foreach ($post_tags as $tag) {
$text .= sprintf('#%s ', $tag->name);
}
}
return $text;
}
Вот этот нехитрый и простой код добавит немного красоты, если вдруг ссылка поста окажется в сообщении телеграма или на стене сообщества в вк, вот примерно такая разница получается:
Если у вас есть какие-нибудь вопросы, то всегда можете написать мне в телеграм Так же подписывайтесь на телеграм канал и если пользуетесь вконтакте, недавно была запущено сообщество, так что так же можете присоединятся.
Всем привет! В рамках реализации задачи по монетизации блога на wordpress мне пришла в голову мысль добавить партнерских программ на свой сайт, пертнерок тех компаний услагами которых я пользуюсь самостоятельно, но для реализации этой задачи нужно немного допилить wordpress, от сторонних плагинов по традиции решил отказаться потому что не хочу =) и к тому же для реализации такой простой задачи достаточно будет возможностей wordpress. Итак, поехали. Далее я опишу процесс создания системы партнерских программ для блога.
Для создания партнерок потребуется создать отдельный справочник записей, те зарегистрировать в системе еще один тип постов:
Открываем functions.php темы и добавляем туда что-то вроде:
После сохранения в админке WP должен появится новый пункт ниже пунтка меню Записи с названием Партнерки. Теперь у нас есть новый зарегистрированный тип записей с минимальным набором полей ( название и изображение ) для добавления наших партнеров.
Но по-мимо изображения и название так же требуется добавления реферальной ссылки, для этого потребуется для нового типа с партнерами зарегистрировать кастомезированые поля записей, поэтому добавляем следующий код в functions.php
Я решил для своей системы добавить еще 2 свойства партнера, комментарий — для внутреннего использования и подсчета количества переходов по моей реферальной ссылке.
Для того чтобы дополнительные поля сохранялись так же требуется добавить следующий хук
add_action('save_post', 'my_extra_fields_save_on_update', 0);
function my_extra_fields_save_on_update($post_id)
{
// базовая проверка
if (
empty($_POST['extra'])
|| !wp_verify_nonce($_POST['extra_fields_nonce'], 'extra_fields_nonce_id')
|| wp_is_post_autosave($post_id) || wp_is_post_revision($post_id)
) {
return false;
}
$extra = $_POST['extra'];
// Все ОК! Теперь, нужно сохранить/удалить данные
// Очищаем все данные
$extra = array_map('sanitize_text_field', $extra);
foreach ($extra as $key => $value) {
// удаляем поле если значение пустое
if (!$value) {
delete_post_meta($post_id, $key);
} else {
update_post_meta($post_id, $key, $value); // add_post_meta() работает автоматически
}
}
return $post_id;
}
Админка готова! Теперь необходимо доработать шаблоны темы, чтобы партнерские программ начали выводится на сайт.
Забыл кое-что, прежде чем переходить к редактированию шаблонов нужно добавить еще функции для выборки партнера и функцию просирования. Для вывода партнерки я буду использовать рандомную выборку одной партнерской программы из всех. При помощи такой нехитрой функции это можно осуществить. Добавляем в functions.php такую функцию
Так как я хочу увеличивать количество переходов на 1 каждый раз при переходе по моей реферальной ссылки требуется добавить функцию проксирования партнерских ссылок. Это можно сделать довольно просто добавив следующий хук в functions.php
Теперь уже точно можно перейти к шаблону сайта. Тут все зависит от сложности шаблона. В моем случае шаблон очень простой поэтому править потребуется не так много
И далее добавляем логику вывода этого шаблона в index.php темы
get_template_part( 'header' );
if ( have_posts() ) :
$i = 1;
while ( have_posts() ) :
the_post();
get_template_part( 'content' );
// If comments are open or we have at least one comment, load up the comment template.
if ( comments_open() || get_comments_number() ) :
comments_template();
endif;
if ($i % 5 == 0) {
get_template_part( 'partner' );
}
$i++;
endwhile;
else :
get_template_part( 'content', 'none' );
endif;
?>
В этом куске кода я скинул шаблон полностью для наглядности, но по-сути вся правка заключается в добавлении вот этой простой логики:
Этот код будет отображать рандомную партнерку после каждых 5 постов
Ну вот и все. Вот один из быстрых и дешевых способов как можно реализовать систему партнерских реферальных программ в своем блоге на WordPress. Конечно подобную систему можно улучшить, а так же в ней есть ряд недостатков, но для начала этого будет достаточно.
А если вам нужна разработка под WP или любая другая помощь по php, можете написать мне в любое время в мой телеграмм на странице профайла
Продолжаю развивать свой сайт. Мне захотелось, чтобы мои новые посты публиковались на канале сайта в телеграм, кстати, кто еще не подписался, подписывайтесь, чтобы следить за обновлениями на сайте.
Скорее всего для WordPress существует куча разных решений для репоста постов с сайта в телеграм, но зачем нам это если мы сами ж программисты, поэтому я сразу решил сделать все своими силами и не прибегать к какому либо готовому решению.
Итак, для репоста в свой телеграм канал, нам потребуется сайт на WordPress, телеграм канал и токен бота, который потребуется получить через папу ботов телеграмма — @BotFather
Открываем @BotFather пишим ему команду
/newbot
В ответ от вас потребуется придумать и ввести имя бота и имя бота с постфексом _bot После этого папа ботов сгенерирует для вас токен для HTTP API
Этот токен мы и будем использовать для нашей системы репостинга обновлений на сайте
после этого требуется отредактировать wp-config.php и добавить туда константу:
define( 'TELEGRAM_BOT_TOKEN', '<TOKEN>' );
<TOKEN> заменить на тот токен, который мы получили при создании нового бота через @BotFather
После этого нам потребуется определить ID канала для того, чтобы передать нашему боту информацию о том в какой чат требуется отправлять сообщения. В моем случае, я использовал закрытый канал, поэтому мне потребовалось выполнить следующие действия для получения ID канала
Добавляем в качестве администратора нашего новорожденного бота на наш канал
Публикуем тестовый пост ( который потом будет не жалко удалить )
В ответ получаем ID нашего чата, который вставляем в wp-config.php
define( 'TELEGRAM_CHANNEL_ID', <ID_CHANNEL> );
Теперь все готово к написанию нашего основного функционала!
Открываем нашу текущую тему WordPress ( предварительно скопировав ее в новую директорию, чтобы обновления темы не затерли наши изменения ) и находим там файл functions.php, в него мы и будем вносить изменения.
В данном случае нас интересуют только новые посты, поэтому мы будем использовать событие WordPress — save_post
Регистрируем новую функцию, которая будет выполнятся каждый раз, когда на сайте будет опубликован новый пост
Эта функция выполняет проверяет является ли пост новым публичным и не ревизией поста и если эти условия выполняются, то вызывается функция message_to_telegram
Эта функция выполняет отправку ссылку и первые 500 символов нового поста в канал телеграм
Ну вот и все, быстрое и минималистичное решение для уведомления о новых постах в телеграм канале. Как это работает можете увидеть на канале, обязательно подпишитесь на него, чтобы не пропустить обновление на сайте.
А если вас интересует создание ботов телеграм или создание сайта на движке wordpress то всегда можете написать мне в телеграм.
Так как появилась задача развивать дальше этот блог, то пришлось решить вопрос с локальным развертыванием сайта локально, поэтому открываю новую рубрику на сайте под названием яждевопс.
Когда-то давно еще во допотоные времена до ядерной войны в 18 веке лет 5 назад мы делали это при помощи вирутальной машины, которая работала через vagrant или вообще разворачивали всю экосистему локально, но сейчас времена наступили другие и появилась докеризация
Если кратко, то докер — это такая прикрасная штука, которая позволяет делать все что позволяла делать виртуальная машина, но более гибко и с меньшими ресурсными затратами. Например можно собрать себе экосистему для запуска определенного программного обеспечения и даже организовать свою изолированную сеть внутри докер системы на вашей локальной машине. О возможностях докера каждый может найти в любой поисковой системе, информации достаточно.
Тут же я хотел продемонстрировать простое решение на докере, которое позволяет развернуть локально такой простой блок на WordPress как этот блог. Итак поехали.
Для начала создаем файл .env с таким содержимым
# префикс, который мы будем использовать для наименования контейнеров в докере
PREFIX=wp
# пароль root для локального контейнера с mysql
MYSQL_ROOT_PASSWORD=somewordpress
# название базы данных root для локального контейнера с mysql
MYSQL_DATABASE=wordpress
# имя пользователя базы данных для локального контейнера с mysql
MYSQL_USER=wordpress
# пароль пользователя базы данных для локального контейнера с mysql
MYSQL_PASSWORD=wordpress
# хоста базы данных на боевом сервере
MYSQL_REMOTE_HOST=remote_host_address
# название базы данных на боевом сервере
MYSQL_REMOTE_DATABASE=remote_wp
# имя пользователя базы данных на боевом сервере
MYSQL_REMOTE_USER=user_db_read
# пароль пользователя базы данных на боевом сервере
MYSQL_REMOTE_PASSWORD=password_db_read
Тут все понятно по комментариям, единственное, что может вызвать вопрос это данные удаленного сервер mysql. Эти данные понадобятся для синхронизации с рабочей базой данных, о котором я напишу ниже. Стоит только отметить, что я рекомендую создать отдельную учетную запись на стороне боевого сервера у которой будет возможность только чтения из базы данных, чтобы в случае утечки этих данных эти данные не могли бы использовать для изменений данных на боевом сервере.
Далее создаем docker-compose.yml
services:
db:
container_name: ${PREFIX}-db
# We use a mariadb image which supports both amd64 & arm64 architecture
image: mariadb:10.6.4-focal
# If you really want to use MySQL, uncomment the following line
#image: mysql:8.0.27
command: '--default-authentication-plugin=mysql_native_password'
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
- MYSQL_ROOT_PASSWORD=${MYSQL_ROOT_PASSWORD}
- MYSQL_DATABASE=${MYSQL_DATABASE}
- MYSQL_USER=${MYSQL_USER}
- MYSQL_PASSWORD=${MYSQL_PASSWORD}
expose:
- 3306
- 33060
ports:
- 3306:3306
- 33060:33060
wordpress:
container_name: ${PREFIX}-wp
image: wordpress:latest
volumes:
- ./www:/var/www/html
ports:
- 8082:80
restart: always
environment:
- WORDPRESS_DB_HOST=db
- WORDPRESS_DB_USER=${MYSQL_DATABASE}
- WORDPRESS_DB_PASSWORD=${MYSQL_PASSWORD}
- WORDPRESS_DB_NAME=${MYSQL_DATABASE}
- WORDPRESS_DEBUG=false
volumes:
db_data:
Это основной файл нашей докер системы при использовании которого будет запущено 2 контейнера, контейнер с базой данных mysql и контейнер с образом wordpress
Все настройки перечислять не буду ( почитаете документацию если будет кому нужно ) отмечу только то что в ports: мы биндим порты на локальную машину http будет доступен на порте 8082, а mysql на порту 3306 так же хочу отметить еще что в секции valumes: контейнера wordpress мы биндим локальную директорию ./www в которой будут хранится файлы wordpress. В нее нужно будет развенуть архив с wordpress или скопировать файлы wordpress с удаленного хостинга.
В итоге у нас получается вот такая директория проекта с файлом .env, docker-compose.yml и директорией www с файлами wordpress, если не хотите прописывать данные доступов к базе данных вручную, то перед запуском сборки докера удалите файл wp-config.php. Контейнер wordpress создаст его вручную и пропишет в него доступы из docker-compose.yml
Далее запускаем вот такую простую команду
$ docker compose up -d
Наслаждаемся процессом скачки образов и сборки контейнеров
Если вам повезло, то после этого можете зайти по адресу http://localhost:8082 откроется ваш wordpress
В принципе на этом можно было бы и закончить, но я настолько ленив, что мне захотелось создать несколько удобных команд для моего проекта, чтобы автоматизировать запуск, пересборку и установку докера, а так же синхронизацию удаленной базы данных ( не зря же я добавил в .env файл параметры MYSQL_REMOTE_*
Итак, чтобы автоматзировать рутинные задачи создадим Makefile.
Makefile — это такая крутая штука, которая была придумана еще в далкие времена, когда программы компилировали, а программисты еще знали как очищать в своих программах память от мусора и что такое язык С. В Makefile можно перечислять инструции которые потом можно выполнять в той директории в которой присутствует этот файл, вот такой Makefile у меня получился
После этого чтобы запустить наш докер с wordpress достаточно будет ввести команду
$ make up
Для того чтобы пересобрать контейнеры
$ make down
Остановить докер
$ make down
И самая интересная команд, команда синхронизации базы данных докера с базой данных боевого сервера
$ make sync
Она удаляет полностью базу данных в докере и полностью забирает ее с боевого хостинга, после этой операции у вас в контейнере базы данных будет полная копия базы боевого сайта с wordpress
В целом это все. Если вдруг возникнут какие-то вопросы и замечания, то можете писать в комменатрии или мне в телеграм, так же если кому-то требуется разработка сайта на wordpress пишите сюда :)
Итак, решил реанимировать свой сайт и заодно подправить страницу профайл и добавил туда блок помощи, кстати, если есть возможность, то можете воспользоваться этой возможностью и поддержать меня.
Сначала добавил обычный текстовый блок, но вряд ли кто-то станет выделять и копировать текст для того чтобы отправить куда-то деньги, тогда я захотел немного упросить процесс и решил подключить javascript для решения этой задачи. От поиска готового решения для WP отказался так как для такой ерунды это не целесообразно, а всевозможные расширения и специальные плагины еще и слишком ресурсоемкие, к тому же я вспомнил что Я Ж программист и решил самостоятельно на коленки сделать свое решение. Как по мне так получилось достаточно неплохо, результат можете посмотреть тут ( а заодно и воспользоваться функционалом =) )